Saturday, 24 July 2010
Measuring and Comparing the Performance of 5 Cloud Platforms
Measuring and Comparing the Performance of 5 Cloud Platforms: "Bitcurrent and Webmetrics have run a number of tests for a month on 5 different cloud platforms - Amazon, Google, Rackspace, Salesforce.com, and Terremark -, attempting to measure the performance of each platform. One of their conclusions is that each platform works better for different application types. By Abel Avram"
Thursday, 22 July 2010
Does the Cloud Need Server Virtualization?
Does the Cloud Need Server Virtualization?: "Simeon Simeonov wrote an essay on the latest strategy of VMWare in the wake of the SpringSource Acquisition 12 months ago. He contends that if Server Virtualization was a key enabler of Cloud Computing, it's days might be counted as VMware CTO Steve Herrod explains “We are committed to making Spring the best language for cloud applications, even if that cloud is not based on VMware vSphere.” By Jean-Jacques Dubray"
Saturday, 17 July 2010
UPDATED: Google Exec Says It's A Good Idea: Open The Index And Speed Up The Internet - SVW
UPDATED: Google Exec Says It's A Good Idea: Open The Index And Speed Up The Internet - SVW: "UPDATED: Google Exec Says It's A Good Idea: Open The Index And Speed Up The Internet"
Friday, 16 July 2010
Whitepaper: Private Cloud Practitioner's Guide
Whitepaper: Private Cloud Practitioner's Guide: "
If you've been following this blog for a while, you know I've been describing how EMC's IT organization is progressing in re-envisioning our IT capabilities based on a private cloud model.
You've seen bits and pieces here on this blog, as well as EMC IT's own web site.
Today, I received a nice white paper entitled "EMC IT's Journey To The Private Cloud: A Practitioner's Guide". While not as complete as many of us would like, it does serve as a nice contextual overview of of our journey: the rationale, the phases and the results to date.
Hope you find it interesting!
"What’s New in CDH3b2: Pig
What’s New in CDH3b2: Pig: "
CDH3 beta 2 includes Pig 0.7.0, the latest and greatest version of the popular dataflow programming environment for Hadoop. In this post I’ll review some of the bigger changes that went into Pig 0.7.0, describe the motivations behind these changes, and explain how they affect users. Readers in search of a canonical list of changes in this new version of Pig should consult the Pig 0.7.0 Release Notes as well as the list of backward incompatible changes.
Load-Store Redesign
The biggest change to appear in Pig 0.7.0 is the complete redesign of the LoadFunc and StoreFunc interfaces. The Load-Store interfaces were first introduced in version 0.1.0 and have remained largely unchanged up to this point. Pig uses a concrete instance of the LoadFunc interface to read Pig records from the underlying storage layer, and similarly uses an instance of the StoreFunc interface when it needs to write a record. Pig provides different LoadFunc and StoreFunc implementations in order to support different storage formats, and since this is a public interface users may provide their own implementations as well.
The primary motivation for redesigning these interfaces is to bring them into closer alignment with Hadoop’s InputFormat and OutputFormat interfaces, with the goal of making it much easier to write new LoadFunc and StoreFunc implementations based on existing Hadoop InputFormat and OutputFormat classes. At the same time the new interfaces were also made a lot more powerful by providing direct access to configurations as well as the ability to selectively read individual columns.
In the short span of time since these new interfaces appeared the Pig community has responded by writing a variety of custom Loaders including ones for Cassandra, Voldemort, and Hive’s RCFile columnar storage format. It is important to note that these new plugins were written without any direct involvement from the Pig core team, which is a significant validation of the work that went into the redesign effort. A list of third-party Pig Loaders is maintained on the Pig Intoperability page. Users who are interested in writing their own LoadFuncs or StoreFuncs should first read the updated Load-Store HowTo.
If you are upgrading from an earlier version of Pig you need to be aware that the new Load/Store interfaces are not backward compatible with the old interfaces. Users who have written custom LoadFuncs or StoreFuncs that work with an earlier version will need to upgrade these functions to use the new interfaces. For more details about this process please consult the Load-Store Migration Guide on the Pig wiki.
Use the Distributed Cache to Improve Performance
Pig 0.7.0 includes a set of important performance enhancements that aim to make queries run faster by leveraging Hadoop’s Distributed Cache. The key observation that motivated these changes is that Pig query plans often involve directing a large number of tasks to read the same sample of data. One can observe this access pattern in the Fragment-Replicate Join, SkewedJoin, and GroupBy operators. Earlier versions of Pig read this data directly from the underlying distributed file system, an approach that is inefficient, but also has the potential to cause a cluster-wide failure if a large number of concurrent Map tasks swamp the NameNode with read requests. PIG-872 and PIG-1218 remedy this problem by loading the common data into the Distributed Cache. This allows tasks to perform a local disk read instead of having to wait while the data is retrieved from HDFS, and also allows tasks that run on the same node to share the same data.
Use Hadoop’s Local Mode for Pig Local Mode
One of things that has made Pig especially easy for new users to pick up is its support for a local mode that does not require an Hadoop installation. Unfortunately, maintaining this feature has turned into a major headache for the Pig developers as it requires a large body of custom code and execution paths that are not shared with the rest of the system. A direct consequence of this is that many of the new features that have been added to Pig do not work in local mode, and this has caused a lot of confusion within the Pig user community. Based on these factors the Pig developers decided that it made sense to replace Pig’s custom local mode implementation with one that depends on Hadoop’s local mode. This change benefits Pig users since they can now test a script in local mode and be confident that it will run correctly in distributed mode, or vice-versa. However, users should be aware that there is one unfortunate side-effect of this change: Pig now runs roughly an order of magnitude slower in local mode.
Making Pig 0.7.0 Even Better
Pig 0.7.0 was released in mid-May, and since that time several important patches have appeared for bugs that were found in the original release. These patches include a fix that allows UDFs to access counters, as well as another fix that adds a counter to track the number of output rows in each output file. I think you’ll be glad to hear that we have included these patches as well as others in the version of Pig 0.7.0 that is included in CDH3 beta 2.
For More Information
We hope you’ll give CDH and Pig a spin. The CDH Quick Start Guide is the best place to begin, followed with the Pig installation instructions in the Pig Installation Guide.
"Tuesday, 13 July 2010
High Performance Computing Hits the Cloud
High Performance Computing Hits the Cloud: "
>

From Perspectives."
High
Performance Computing (HPC) is
defined by Wikipedia as:
High-performance computing
(HPC) uses supercomputers and computer
clusters to solve advanced computation
problems. Today, computer systems approaching the teraflops-region
are counted as HPC-computers. The term is most commonly associated with computing
used for scientific research or computational
science. A related term, high-performance
technical computing (HPTC),
generally refers to the engineering applications of cluster-based computing (such
as computational
fluid dynamics and the building
and testing of virtual prototypes).
Recently, HPC has come to be applied to business uses
of cluster-based supercomputers, such as data
warehouses, line-of-business
(LOB) applications, and transaction
processing.
Predictably, I use the broadest
definition of HPC including data intensive computing and all forms of computational
science. It still includes the old stalwart applications of weather modeling and weapons
research but the broader definition takes HPC from a niche market to being a big part
of the future of server-side computing. Multi-thousand node clusters, operating at
teraflop rates, running simulations over massive data sets is how petroleum exploration
is done, it’s how advanced financial instruments are (partly) understood, it’s how
brick and mortar retailers do shelf space layout and optimize their logistics chains,
it’s how automobile manufacturers design safer cars through crash simulation, it’s
how semiconductor designs are simulated, it’s how aircraft engines are engineered
to be more fuel efficient, and it’s how credit card companies measure fraud risk.
Today, at the core of any well run business, is a massive data store –they all have
that. The measure of a truly advanced company is the depth of analysis, simulation,
and modeling run against this data store. HPC
workloads are incredibly important today and the market segment is growing very quickly
driven by the plunging cost of computing and the business value understanding large
data sets deeply.

High Performance Computing is one of those
important workloads that many argue can’t move to the cloud. Interestingly, HPC has
had a long history of supposedly not being able to make a transition and then, subsequently,
making that transition faster than even the most optimistic would have guessed possible.
In the early days of HPC, most of the workloads were run on supercomputers.
These are purpose built, scale-up servers made famous by Control
Data Corporation and later by Cray
Research with the Cray
1 broadly covered in
the popular press. At that time, many argued that slow processors and poor performing
interconnects would prevent computational clusters from ever being relevant for these
workloads. Today more than ¾ of the fastest HPC systems in the world are based upon
commodity compute clusters.
The HPC community uses the Top-500 list
as the tracking mechanism for the fastest systems in the world. The goal of the Top-500
is to provide a scale and performance metric for a given HPC system. Like all benchmarks,
it is a good thing in that it removes some of the manufacturer hype but benchmarks
always fail to fully characterize all workloads. They abstract performance to a single
or small set of metrics which is useful but this summary data can’t faithfully represent
all possible workloads. Nonetheless, in many communities including HPC and Relational
Database Management Systems, benchmarks
have become quite important. The HPC world uses the Top-500
list which depends upon LINPACK as
the benchmark.
Looking at the most recent Top-500
list published in June 2010, we see that Intel processors now dominate the list with
81.6% of the entries. It is very clear that the HPC move to commodity clusters has
happened. The move that “couldn’t happen” is near complete and the vast majority of
very high scale HPC systems are now based upon commodity processors.
What about HPC in the cloud, the
next “it can’t happen” for HPC? In many respects, HPC workloads are a natural for
the cloud in that they are incredibly high scale and consume vast machine resources.
Some HPC workloads are incredibly spiky with mammoth clusters being needed for only
short periods of time. For example semiconductor design simulation workloads are incredibly
computationally intensive and need to be run at high-scale but only during some phases
of the design cycle. Having more resources to throw at the problem can get a design
completed more quickly and possibly allow just one more verification run to potentially
save millions by avoiding a design flaw. Using
cloud resources, this massive fleet of servers can change size over the course of
the project or be freed up when they are no longer productively needed. Cloud computing
is ideal for these workloads.
Other HPC uses tend to be more steady state
and yet these workloads still gain real economic advantage from the economies of extreme
scale available in the cloud. See Cloud
Computing Economies of Scale (talk, video)
for more detail.
When I dig deeper into “steady state HPC workloads”,
I often learn they are steady state as an existing constraint rather than by the fundamental
nature of the work. Is there ever value in running one more simulation or one more
modeling run a day? If someone on the team got a good idea or had a new approach to
the problem, would it be worth being able to test that theory on real data without
interrupting the production runs? More resources, if not accompanied by additional
capital expense or long term utilization commitment, are often valuable even for what
we typically call steady state workloads. For example, I’m guessing BP,
as it battles the Gulf
of Mexico oil spill,
is running more oil well simulations and tidal flow analysis jobs than originally
called for in their 2010 server capacity plan.
No workload is flat and unchanging.
It’s just a product of a highly constrained model that can’t adapt quickly to changing
workload quantities. It’s a model from the past.
There is no question there is value to being
able to run HPC workloads in the cloud. What makes many folks view HPC as non-cloud
hostable is these workloads need high performance, direct access to underlying server
hardware without the overhead of the virtualization common in most cloud computing
offerings and many of these applications need very high bandwidth, low latency networking.
A big step towards this goal was made earlier today when Amazon
Web Services announced the EC2
Cluster Compute Instance
type.
The cc1.4xlarge instance specification:
· 23GB
of 1333MHz DDR3 Registered ECC
· 64GB/s
main memory bandwidth
· 2
x Intel Xeon X5570 (quad-core Nehalem)
· 2
x 845GB 7200RPM HDDs
· 10Gbps
Ethernet Network Interface
It’s this last point that I’m particularly
excited about. The difference between just a bunch of servers in the cloud and a high
performance cluster is the network. Bringing 10GigE direct to the host isn’t that
common in the cloud but it’s not particularly remarkable. What is more noteworthy
is it is a full bisection
bandwidth network within the cluster. It
is common industry practice to statistically
multiplex network traffic over
an expensive network core with far less than full bisection bandwidth. Essentially,
a gamble is made that not all servers in the cluster will transmit at full interface
speed at the same time. For many workloads this actually is a good bet and one that
can be safely made. For HPC workloads and other data intensive applications like Hadoop,
it’s a poor assumption and leads to vast wasted compute resources waiting on a poor
performing network.
Why provide less than full bisection bandwidth? Basically,
it’s a cost problem. Because networking gear is still building on a mainframe design
point, it’s incredibly expensive. As a consequence, these precious resources need
to be very carefully managed and over-subscription levels of 60 to 1 or even over
100 to 1 are common. See Datacenter
Networks are in my Way for
more on this theme.
For me, the most interesting aspect
of the newly announced Cluster Compute instance type is not the instance at all. It’s
the network. These servers are on a full bisection bandwidth cluster network. All
hosts in a cluster can communicate with other nodes in the cluster at the full capacity
of the 10Gbps fabric at the same time without blocking. Clearly not all can communicate
with a single member of the fleet at the same time but the network can support all
members of the cluster communicating at full bandwidth in unison. It’s a sweet network
and it’s the network that makes this a truly interesting HPC solution.
Each Cluster Compute Instance
is $1.60 per instance hour. It’s now possible to access millions of dollars of servers
connected by a high performance, full bisection bandwidth network inexpensively. An
hour with a 1,000 node high performance cluster for $1,600. Amazing.
As a test of the instance type
and network prior to going into beta Matt Klein, one of the HPC team engineers, cranked
up LINPACK using an 880 server sub-cluster. It’s a good test in that it stresses the
network and yields a comparative performance metric. I’m not sure what Matt expected
when he started the run but the result he got just about knocked me off my chair when
he sent it to me last Sunday. Matt’s
experiment yielded a booming 41.82 TFlop Top-500
run.
For those of you as excited as I am interested in the details from the
Top-500 LINPACK run:
In: Amazon_EC2_Cluster_Compute_Instances_Top500_hpccinf.txt
Out: Amazon_EC2_Cluster_Compute_Instances_Top500_hpccoutf.txt
The announcement: Announcing
Cluster Compute Instances for EC2
This is phenomenal performance for a pay-as-you-go EC2 instance. But
what makes it much more impressive is that result would place the EC2 Cluster Compute
instance at #146 on the Top-500.
It also appears to scale well which is to say bigger numbers look feasible if more
nodes were allocated to LINPACK testing. As fun as that would be, it is time to turn
all these servers over to customers so we won’t get another run but it was fun.
>
You can now have one of the biggest
super computers in the world for your own private use for $1.60 per instance per hour.
I love what’s possible these days.
Welcome to the cloud, HPC!
--jrh
b: http://blog.mvdirona.com / http://perspectives.mvdirona.com
From Perspectives."
DbShards Part Deux - The Internals
DbShards Part Deux - The Internals: "


 "
"
This is a follow up article by Cory Isaacson to the first article on DbShards, Product: dbShards - Share Nothing. Shard Everything, describing some of the details about how DbShards works on the inside.
The dbShards architecture is a true “shared nothing” implementation of Database Sharding. The high-level view of dbShards is shown here: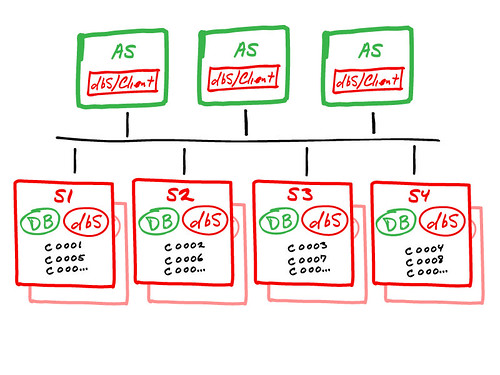
The above diagram shows how dbShards works for achieving massive database scalability across multiple database servers, using native DBMS engines and our dbShards components. The important components are:
Expanding the Cloud - Cluster Compute Instances for Amazon EC2
Expanding the Cloud - Cluster Compute Instances for Amazon EC2: "
Today, Amazon Web Services took very an important step in unlocking the advantages of cloud computing for a very important application area. Cluster Computer Instances for Amazon EC2 are a new instance type specifically designed for High Performance Computing applications. Customers with complex computational workloads such as tightly coupled, parallel processes, or with applications that are very sensitive to network performance, can now achieve the same high compute and networking performance provided by custom-built infrastructure while benefiting from the elasticity, flexibility and cost advantages of Amazon EC2
During my academic career, I spent many years working on HPC technologies such as user-level networking interfaces, large scale high-speed interconnects, HPC software stacks, etc. In those days, my main goal was to take the advances in building the highly dedicated High Performance Cluster environments and turn them into commodity technologies for the enterprise to use. Not just for HPC but for mission critical enterprise systems such as OLTP. Today, I am very proud to be a part of the Amazon Web Services team as we truly make HPC available as an on-demand commodity for every developer to use.
HPC and Amazon EC2
Almost immediately after the launch of Amazon EC2, our customers started to use it for High Performance Computing. Early users included some Wall Street firms who knew exactly how to balance the scale of computation against the quality of the results they needed to create a competitive edge. They have run thousands of instances of complex Monte Carlo simulations at night to determine how to be ready at market open. Other industries using Amazon EC2 for HPC-style workloads include pharmaceuticals, oil exploration, industrial and automotive design, media and entertainment, and more.
Further computationally intensive, highly parallel workloads have found their way to Amazon EC2 as businesses have explored using HPC types of algorithms for other application categories, for example to to process very large unstructured data sets for Business Intelligence applications. This has led to strong growth in the popularity of Hadoop and Map Reduce technologies, including Amazon Elastic Map Reduce as a tool for making it easy to run these compute jobs by taking away much of the heavy lifting normally associated with running large Hadoop clusters.
As much as Amazon EC2 and Elastic Map Reduce have been successful in freeing some HPC customers with highly parallelized workloads from the typical challenges of HPC infrastructure in capital investment and the associated heavy operation lifting, there were several classes of HPC workloads for which the existing instance types of Amazon EC2 have not been the right solution. In particular this has been true for applications based on algorithms - often MPI-based - that depend on frequent low-latency communication and/or require significant cross sectional bandwidth. Additionally, many high-end HPC applications take advantage of knowing their in-house hardware platforms to achieve major speedup by exploiting the specific processor architecture. There has been no easy way for developers to do this in Amazon EC2... until today.
Introducing Cluster Compute Instances for Amazon EC2
Cluster Computer Instances are similar to other Amazon EC2 instances but have been specifically engineered to provide high performance compute and networking. Cluster Compute Instances can be grouped as cluster using a 'cluster placement group' to indicate that these are instances that require low-latency, high bandwidth communication. When instances are placed in a cluster they have access to low latency, non-blocking 10 Gbps networking when communicating the other instances in the cluster.
Next, Cluster Compute Instances are specified down to the processor type so developers can squeeze optimal performance out of them using compiler architecture-specific optimizations. At launch Cluster Computer Instances for Amazon EC2 will have 2 Intel Xeon X5570 (also known as quad core i7 or Nehalem) processors.
Unlocking the benefits of the cloud for the HPC community
Cluster Compute Instances for Amazon EC2 change the HPC game for two important reasons:
Access to scalable on-demand capacity
Dedicated High Performance Compute clusters require significant capital investments and their procurement often has longer lead times than many enterprise class server systems. This means that most HPC systems are constrained in one or more dimensions by the time that they become operational. As a result, HPC systems are typically shared resources with long queues of jobs waiting to be executed and many users have to be very careful not to exceed their capacity allocation for that period.
Cluster Compute Instances for Amazon EC2 bring the advantages of cloud computing to this class of High Performance Computing removing the need for upfront capital investments and giving users access to HPC capacity on demand at the exact scale that they require for their application.
Commoditizing the management of HPC resources
Traditionally we have thought about HPC as the domain of extreme specialism; the kind of research that only happens at places such as the US National Research Labs. These labs have access to some of the world's fastest supercomputers and have dedicated staff to keep them running and fully loaded 365 days a year. But there is a much larger category of potential HPC users beyond these top supercomputer specialists, including even within the more mid-range HPC workloads of these labs such as Lawrence Berkeley National Labs where they have been early successful users of the new Cluster Compute Instances.
Many organizations are using mid-range HPC systems for their enterprise and research needs. Given the specialized nature of these platforms, they require dedicated resources to maintain and operate and put a big burden on the IT organization. Cluster Compute Instances for Amazon EC2 removes the heavy lifting of the operational burden typically associated with HPC systems. There is no more need for hardware tinkering to keep the clusters up and running (I spent many nights doing this; there is no glory in it). These instance types are managed exactly the way other Amazon EC2 instances are managed which allows users to capitalize on the investment they have already made in that area.
More information
If you are looking for more information on Cluster Compute Instances for Amazon EC2 visit our HPC Solutions page. Jeff Barr in his blog post on the AWS developer blog has additional details and there are some great testimonials of early Cluster Compute Instances customers in the press release.
Monday, 12 July 2010
Making data Vanish
Making data Vanish: "
Copyright © 2010 StorageMojo. This Feed is for personal non-commercial use only. If you are not reading this material in your news aggregator, the site you are looking at is guilty of copyright infringement. Please contact legal@storagemojo.com so we can take legal action immediately.
Plugin by Taragana
Given how hard it is to save data you want (see The Universe hates your data) to keep, losing data on the web should be easy. It isn’t, because it gets stored so many places in its travels.
Problem
But the power of the web means that silliness can now be stored and found with the speed of a Google search. You don’t want sexy love notes – or pictures – to a former flame posted after infatuation ends.
Or maybe you want to discuss relationship, health or work problems with a friend over email – and don’t want your musings to be later shared with others. Wouldn’t it be nice to know that such messages will become unreadable even if your friend is unreliable?
Researchers built a prototype service – Vanish – that seeks to:
. . . ensure that all copies of certain data become unreadable after a user-specified time, without any specific action on the part of a user, without needing to trust any single third party to perform the deletion, and even if an attacker obtains both a cached copy of that data and the user’s cryptographic keys and passwords.
That’s a tall order. Their 1st proof-of-concept failed. But they are continuing the fight.
Vanish
In Vanish: Increasing Data Privacy with Self-Destructing Data Roxana Geambasu, Tadayoshi Kohno, Amit A. Levy and Henry M. Levy of the University of Washington computer science department present an architecture and a prototype to do just that.
Ironically, the project utilizes the same P2P infrastructures that preserves and distribute data: BitTorrent’s VUZE distributed hash table (DHT) client.
The basic idea is this: Vanish encrypts your data with a random key, destroys the key, and then sprinkles pieces of the key across random nodes of the DHT. You tell the system when to destroy the key and your data goes poof!
They developed a data structure called a Vanishing Data Object (VDO) that encapsulates user data and prevents the content from persisting. And the data becomes unreadable even if the attacker gets a pristine copy of the VDO from before its expiration and all the associated keys and passwords.
Here’s a timeline for that attack:

DHT overview
A DHT is a distributed, peer-to-peer (P2P) storage network. . . . DHTs like Vuze generally exhibit a put/get interface for reading and storing data, which is implemented internally by three operations:lookup, get, andstore. The data itself consists of an (index, value) pair. Each node in the DHT manages a part of an astronomically large index name space (e.g., 2160 values for Vuze).
DHTs are available, scalable, broadly distributed and decentralized with rapid node churn. All these properties are ideal for an infrastructure that has to withstand a wide variety of attacks.
Vanish architecture
Data (D) is encrypted (E) with key (K) to deliver cyphertext (C). Then K is split into N shares – K1,…,KN – and distributed across the DHT using a random access key (L) and a secure pseudo-random number generator. The K split uses a redundant erasure code so that a user definable subset of N shares can reconstruct the key.
The erasure codes are needed because DHTs lose data due to node churn. It is a bug that is also a feature for secure destruction of data.
Prototype
They built a Firefox plug-in for Gmail to create self-destructing emails and another – FireVanish – for making any text in a web input box self-destructing. They also built a file app, so you can make any file self-destructing. Handy for Word backup files that you don’t want to keep around.
The major change to the Vuze BitTorrent client was less than 50 lines of code to prevent lookup sniffing attacks. Those changes only affect the client, not the DHT.
The Vanish proto was cracked by a group of researchers at UT Austin, Princeton, and U of Michigan. They found that an eavesdropper could collect the key shards from the DHT and reassemble the “vanished” content.
Who is going to collect all the shard-like pieces on DHTs? Other than the NSA and other major intelligence services, probably no one. For extra security the data can be encrypted before VDO encapsulation.
The StorageMojo take
The Internet is paid for with our loss of privacy. Young people may think it no great loss, check back in 20 years and we’ll see what you think then.
It is slowly dawning on the public that their lives are an open book on the Internet. Expect a growing market for private communication and storage if ease-of-use and trust issues can be resolved.
You don’t have to be Tiger Woods to want to keep your private life private. I hope the Vanish team succeeds.
Courteous comments welcome, of course. Figures courtesy of the Vanish team.
Copyright © 2010 StorageMojo. This Feed is for personal non-commercial use only. If you are not reading this material in your news aggregator, the site you are looking at is guilty of copyright infringement. Please contact legal@storagemojo.com so we can take legal action immediately.
Plugin by Taragana
Related posts:
- MaxiScale’s Web-scale file system A new web scale – they claim linear scaling to...
- Avere Systems: dynamic tiering for the masses – of data? Last week RisingTide Systems, a stealth startup with no web...
- A RisingTide lifts all clouds Check out their homepage and, as of today, “This page...
Related posts brought to you by Yet Another Related Posts Plugin.
"Long tailed workloads and the return of hierarchical storage management
Long tailed workloads and the return of hierarchical storage management: "

From Perspectives."
Hierarchical
storage management (HSM) also called
tiered storage management is back but in a different form. HSM exploits the access
pattern skew across data sets by placing cold, seldom accessed data on slow cheap
media and frequently accessed data on fast near media. In
old days, HSM typically referred to system mixing robotically managed tape libraries
with hard disk drive staging areas. HSM was actually never gone – its just a very
old technique to exploit data access pattern skew to reduce storage costs. Here’s
an old unit from FermiLab.

Hot data or data currently being
accessed is stored on disk and old data that has not been recently accessed is stored
on tape. It’s a great way to drive costs down below disk but avoid the people costs
of tape library management and to (slightly) reduce the latency of accessing data
on tape.
The basic concept shows up anywhere where
there is data access locality or skew in the access patterns where some data is rarely
accessed and some data is frequently accessed. Since evenly distributed, non-skewed
access pattern only show up in benchmarks, this concept works on a wide variety of
workloads. Processors have cache hierarchies where the top of the hierarchy is very
expensive register files and there are multiple layers of increasingly large caches
between the register file and memory. Database management systems have large in memory
buffer pools insulating access to slow disk. Many very high scale services like Facebook
have mammoth in-memory caches insulating access to slow database systems. In the Facebook
example, they have 2TB of Memcached in front of their vast MySQL fleet: Velocity
2010.
Flash memory again opens up the opportunity
to apply HSM concepts to storage. Rather
than using slow tape and fast disk, we use (relatively) slow disk and fast NAND flash.
There are many approaches to implementing HSM over flash memory and hard disk drives.
Facebook implemented Flashcache which
tracks access patterns at the logical volume layer (below the filesystem) in Linux
with hot pages written to flash and cold pages to disk. LSI
is a good example implementation done at the disk controller level with their CacheCade product.
Others have done it in application specific logic where hot indexing structures are
put on flash and cold data pages are written to disk. Yet another approach that showed
up around 3 years ago is a Hybrid
Disk Drive.
Hybrid drives combine large, persistent
flash memory caches with disk drives in a single package. When they were first announced,
I was excited by them but I got over the excitement once I started benchmarking. It
was what looked to be a good idea but the performance really was unimpressive.
Hybrid rives still looks like a good idea
but now we actually have respectable performance with the Seagate
Momentus XT. This part is actually
aimed at the laptop market but I’m always watching client progress to understand what
can be applied to servers. This finally looks like its heading in the right direction. See
the AnandTech article on this drive for more performance data: Seagate's
Momentus XT Reviewed, Finally a Good Hybrid HDD.
I still slightly prefer the Facebook FlashCache approach but these hybrid drives are
worth watching.
Thanks to Greg
Linden for sending
this one my way.
--jrh
b: http://blog.mvdirona.com / http://perspectives.mvdirona.com
From Perspectives."
What’s new in CDH3 b2: HBase
What’s new in CDH3 b2: HBase: "
Over the last two years, Cloudera has helped a great number of customers achieve their business objectives on the Hadoop platform. In doing so, we’ve confirmed time and time again that HDFS and MapReduce provide an incredible platform for batch data analysis and other throughput-oriented workloads. However, these systems don’t inherently provide subsecond response times or allow random-access updates to existing datasets. HBase, one of the new components in CDH3b2, addresses these limitations by providing a real time access layer to data on the Hadoop platform.
HBase is a distributed database modeled after BigTable, an architecture that has been in use for hundreds of production applications at Google since 2006. The primary goal of HBase is simple: HBase provides an immensely scalable data store with soft real-time random reads and writes, a flexible data model suitable for structured or complex data, and strong consistency semantics for each row. As HBase is built on top of the proven HDFS distributed storage system, it can easily scale to many TBs of data, transparently handling replicated storage, failure recovery, and data integrity.
In this post I’d like to highlight two common use cases for which we think HBase will be particularly effective:
Analysis of continuously updated data
Many applications need to analyze data that is always changing. For example, an online retail or web presence has a set of customers, visitors, and products that is constantly being updated as users browse and complete transactions. Social or graph-analysis applications may have an ever-evolving set of connections between users and content as new relationships are discovered. In web mining applications, crawlers ingest newly updated web pages, RSS feeds, and mailing lists.
With data access methods available for all major languages, it’s simple to interface data-generating applications like web crawlers, log collectors, or web applications to write into HBase. For example, the next generation of the Nutch web crawler stores its data in HBase. Once the data generators insert the data, HBase enables MapReduce analysis on either the latest data or a snapshot at any recent timestamp.
User-facing analytics
Most traditional data warehouses focus on enabling businesses to analyze their data in order to make better business decisions. Some algorithm or aggregation is run on raw data to generate rollups, reports, or statistics giving internal decision-makers better information on which to base product direction, design, or planning. Hadoop enables those traditional business intelligence use cases, but also enables data mining applications that feed directly back into the the core product or customer experience. For example, LinkedIn uses Hadoop to compute the “people you may know” feature, improving connectivity inside their social graph. Facebook, Yahoo, and other web properties use Hadoop to compute content- and ad-targeting models to improve stickiness and conversion rates.
These user-facing data applications rely on the ability not just to compute the models, but also to make the computed data available for latency-sensitive lookup operations. For these applications, it’s simple to integrate HBase as the destination for a MapReduce job. Extremely efficient incremental and bulk loading features allow the operational data to be updated while simultaneously serving traffic to latency-sensitive workloads. Compared with alternative data stores, the tight integration with other Hadoop projects as well as the consolidation of infrastructure are tangible benefits.
HBase in CDH3 b2
We at Cloudera are pretty excited about HBase, and are happy to announce it as a first class component in Cloudera’s Distribution for Hadoop v3. HBase is a younger project than other ecosystem projects, but we are committed to doing the work necessary to stabilize and improve it to the same level of robustness and operability as you are used to with the rest of the Cloudera platform.
Since the beginning of this year, we have put significant engineering into the HBase project, and will continue to do so for the future. Among the improvements contributed by Cloudera and newly available in CDH3 b2 are:
- HDFS improvements for HBase – along with the HDFS team at Facebook, we have contributed a number of important bug fixes and improvements for HDFS specifically to enable and improve HBase. These fixes include a working sync feature that allows full durability of every HBase edit, plus numerous performance and reliability fixes.
- Failure-testing frameworks – we have been testing HBase and HDFS under a variety of simulated failure conditions in our lab using a new framework called gremlins. Our mantra is that if HBase can remain available on a cluster infested with gremlins, it will be ultra-stable on customer clusters as well.
- Incremental bulk load – this feature allows efficient bulk load from MapReduce jobs into existing tables.
What’s up next for HBase in CDH3?
Our top priorities for HBase right now are stability, reliability, and operability. To that end, some of the projects we’re currently working on with the rest of the community are:
- Improved Master failover – the HBase master already has automatic failover capability – the HBase team is working on improving the reliability of this feature by tighter integration with Apache ZooKeeper.
- Continued fault testing and bug fixing – the fault testing effort done over the last several months has exposed some bugs that aren’t yet solved – we’ll fix these before marking CDH3 stable.
- Better operator tools and monitoring – work is proceeding on an hbck tool (similar to filesystem fsck) that allows operators to detect and repair errors on a cluster. We’re also improving monitoring and tracing to better understand HBase performance in production systems.
And, as Charles mentioned, we see CDH as a holistic data platform. To that end, several integration projects are already under way:
- Flume integration – capture logs from application servers directly into HBase
- Sqoop integration – efficiently import data from relational databases into HBase
- Hive integration – write queries in a familiar SQL dialect in order to analyze data stored in HBase.
Get HBase
If HBase sounds like it’s a good fit for one of your use cases, I encourage you to head on over to the HBase install guide and try it out today. I’d also welcome any feedback you have – HBase, like CDH3 b2, is still in a beta form, and your feedback is invaluable for improving it as we march towards stability.
"Sunday, 11 July 2010
Metamorphic code: Information from Answers.com
Metamorphic code: Information from Answers.com
While polymorphic viruses cipher their functional code to avoid pattern recognition, such a virus will still need to decipher the code - unmodified from infection to infection - in order to execute. Metamorphic viruses change their code to an equivalent one (i.e. a code doing essentially the same thing), so that a mutated virus never has the same executable code in memory (not even at runtime) as the original virus that constructed the mutation. This modification can be achieved using techniques like inserting NOP instructions, swapping registers, changing flow control with jumps or reordering independent instructions. Metamorphic code is usually more effective than polymorphic code. Unlike with polymorphic viruses, anti-virus products may not simply use emulation techniques to defeat metamorphism, since metamorphic code may never reveal code that remains constant from infection to infection.
Thursday, 8 July 2010
Strategy: Recompute Instead of Remember Big Data
Strategy: Recompute Instead of Remember Big Data: "
 "
"
Professor Lance Fortnow, in his blog post Drowning in Data, says complexity has taught him this lesson: When storage is expensive, it is cheaper to recompute what you've already computed. And that's the world we now live in: Storage is pretty cheap but data acquisition and computation are even cheaper.
Jouni, one of the commenters, thinks the opposite is true: storage is cheap, but computation is expensive. When you are dealing with massive data, the size of the data set is very often determined by the amount of computing power available for a certain price. With such data, a linear-time algorithm takes O(1) seconds to finish, while a quadratic-time algorithm requires O(n) seconds. But as computing power increases exponentially over time, the quadratic algorithm gets exponentially slower.
For me it's not a matter of which is true, both positions can be true, but what's interesting is to think that storage and computation are in some cases fungible. Your architecture can decide which tradeoffs to make based on the cost of resources and the nature of your data. I'm not sure, but this seems like a new degree of freedom in the design space.
Sunday, 4 July 2010
Hadoop Summit 2010
I didn’t attend the Hadoop Summit this year or last but was at the inaugural event back in 2008 and it was excellent. This year, the Hadoop Summit 2010 was held June 29 again in Santa Clara. This agenda for the 2010 event is at: Hadoop Summit 2010 Agenda. Since I wasn’t able to be there, Adam Gray of the Amazon AWS team was kind enough to pass on his notes and let me use them here:
Key Takeaways
· Yahoo and Facebook operate the world largest Hadoop clusters, 4,000/2,300 nodes with 70/40 petabytes respectively. They run full cluster replicas to assure availability and data durability.
· Yahoo released Hadoop security features with Kerberos integration which is most useful for long running multitenant Hadoop clusters.
· Cloudera released paid enterprise version of Hadoop with cluster management tools and several dB connectors and announced support for Hadoop security.
· Amazon Elastic MapReduce announced expand/shrink cluster functionality and paid support.
· Many Hadoop users use the service in conjunction with NoSQL DBs like Hbase or Cassandra.
Keynotes
Yahoo had the opening keynote with talks by Blake Irving, Chief Products Officer, Shelton Shugar, SVP of Cloud Computing, and Eric Baldeschwieler, VP of Hadoop. They talked about Yahoo’s scale, including 38k Hadoop servers, 70 PB of storage, and more than 1 million monthly jobs, with half of those jobs written in Apache Pig. Further their agility is improving significantly despite this massive scale—within 7 minutes of a homepage click they have a completely reconfigured preference model for that user and an updated homepage. This would not be possible without Hadoop. Yahoo believes that Hadoop is ready for enterprise use at massive scale and that their use case proves it. Further, a recent study found that 50% of enterprise companies are strongly considering Hadoop, with the most commonly cited reason being agility. Initiatives over the last year include: further investment and improvement in Hadoop 0.20, integration of Hadoop with Kerberos, and the Oozie workflow engine.
Next, Peter Sirota gave a keynote for Amazon Elastic MapReduce that focused on how the service makes combining the massive scalability of MapReduce with the web-scale infrastructure of AWS more accessible, particularly to enterprise customers. He also announced several new features including expanding and shrinking the cluster size of running job flows, support for spot instances, and premium support for Elastic MapReduce. Further, he discussed Elastic MapReduce’s involvement in the ecosystem including integration with Karmasphere and Datameer. Finally, Scott Capiello, Senior Director of Products at Microstrategy, came on stage to discuss their integration with Elastic MapReduce.
Cloudera followed with talks by Doug Cutting, the creator of Hadoop, and Charles Zedlweski, Senior Director of Product Management. They announced Cloudera Enterprise, a version of their software that includes production support and additional management tools. These tools include improved data integration and authorization management that leverages Hadoops security updates. And they demoed a WebUI for using these management tools.
The final keynote was given by Mike Schroepfer, VP of Engineering at Facebook. He talked about Facebook’s scale with 36 PB of uncompressed storage, 2,250 machines with 23k processors, and 80-90 TB growth per day. Their biggest challenge is in getting all that data into Hadoop clusters. Once the data is there, 95% of their jobs are Hive-based. In order to ensure reliability they replicate critical clusters in their entirety. As far as traffic, the average user spends more time on Facebook than the next 6 web pages combined. In order to improve user experience Facebook is continually improving the response time of their Hadoop jobs. Currently updates can occur within 5 minutes; however, they see this eventually moving below 1 minute. As this is often an acceptable wait time for changes to occur on a webpage, this will open up a whole new class of applications.
Discussion Tracks
After lunch the conference broke into three distinct discussion tracks: Developers, Applications, and Research. These tracks had several interesting talks including one by Jay Kreps, Principal Engineer at LinkedIn, who discussed LinkedIn’s data applications and infrastructure. He believes that their business data is ideally suited for Hadoop due to its massive scale but relatively static nature. This supports large amounts of computation being done offline. Further, he talked about their use of machine learning to predict relationships between users. This requires scoring 120 billion relationships each day using 82 Hadoop jobs. Lastly, he talked about LinkedIn’s in-house developed workflow management tool, Azkaban, an alternative to Oozie.
Eric Sammer, Solutions Architect at Cloudera, discussed some best practices for dealing with massive data in Hadoop. Particularly, he discussed the value of using workflows for complex jobs, incremental merges to reduce data transfer, and the use of Sqoop (SQL to Hadoop) for bulk relational database imports and exports. Yahoo’s Amit Phadke discussed using Hadoop to optimize online content. His recommendations included leveraging Pig to abstract out the details of MapReduce for complex jobs and taking advantage of the parallelism of HBase for storage. There was also significant interest in the challenges of using Hadoop for graph algorithms including a talk that was so full that they were unable to let additional people in.
Elastic MapReduce Customer Panel
The final session was a customer panel of current Amazon Elastic MapReduce users chaired by Deepak Singh. Participants included: Netflix, Razorfish, Coldlight Solutions, and Spiral Genetics. Highlights include:
· Razorfish discussed a case study in which a combination of Elastic MapReduce and cascading allowed them to take a customer to market in half the time with a 500% return in ad spend. They discussed how using EMR has given them much better visibility into their costs, allowing them to pass this transparency on to customers.
· Netflix discussed their use of Elastic MapRedudce to setup a hive-based data warehouseing infrastructure. They keep a persistent cluster with data backups in S3 to ensure durability. Further, they also reduce the amount of data transfer through pre-aggregation and preprocessing of data.
· Spiral Genetics talked about they had to leverage AWS to reduce capital expenditures. By using Amazon Elastic MapReduce they were able to setup a running job in 3 hours. They are also excited to see spot instance integration.
· Coldlight Solutions said that buying $1/2M in infrastructure wasn’t even an option when they started. Now it is, but they would rather focus on their strength: machine learning and Amazon Elastic MapReduce allows them to do this.
Saturday, 3 July 2010
Filesystem Interfaces to NoSQL Solutions
Filesystem Interfaces to NoSQL Solutions: "



 "
"
Sounds like it is becoming a trend. So far we have:
Jeff Darcy explains why having a filesystem interface to NoSQL storage can make sense:
Voldemort is pretty easy to use, but providing a filesystem interface makes it possible for even “naive” programs that know nothing about Voldemort to access data stored there. It also provides things like directories, UNIX-style owners and groups, and byte-level access to arbitrarily large files. Lastly, it handles some common contention/consistency issues in what I hope is a useful way, instead of requiring the application to deal with those issues itself.
Subscribe to:
Posts (Atom)