The Power of B-trees
CouchDB uses a data structure called a B-tree to index its documents and views. We’ll look at B-trees enough to understand the types of queries they support and how they are a good fit for CouchDB.
This is our first foray into CouchDB internals. To use CouchDB, you don’t need to know what’s going on under the hood, but if you understand how CouchDB performs its magic, you’ll be able to pull tricks of your own. Additionally, if you understand the consequences of the ways you are using CouchDB, you will end up with smarter systems.
If you weren’t looking closely, CouchDB would appear to be a B-tree manager with an HTTP interface.
CouchDB is actually using a B+ tree, which is a slight variation of the B-tree that trades a bit of (disk) space for speed. When we say B-tree, we mean CouchDB’s B+ tree.
A B-tree is an excellent data structure for storing huge amounts of data for fast retrieval. When there are millions and billions of items in a B-tree, that’s when they get fun. B-trees are usually a shallow but wide data structure. While other trees can grow very high, a typical B-tree has a single-digit height, even with millions of entries. This is particularly interesting for CouchDB, where the leaves of the tree are stored on a slow medium such as a hard drive. Accessing any part of the tree for reading or writing requires visiting only a few nodes, which translates to a few head seeks (which are what make a hard drive slow), and because the operating system is likely to cache the upper tree nodes anyway, only the seek to the final leaf node is needed.
CouchDB’s B-tree implementation is a bit different from the original. While it maintains all of the important properties, it adds Multi-Version Concurrency Control (MVCC) and an append-only design. B-trees are used to store the main database file as well as view indexes. One database is one B-tree, and one view index is one B-tree.
MVCC allows concurrent reads and writes without using a locking system. Writes are serialized, allowing only one write operation at any point in time for any single database. Write operations do not block reads, and there can be any number of read operations at any time. Each read operation is guaranteed a consistent view of the database. How this is accomplished is at the core of CouchDB’s storage model.
The short answer is that because CouchDB uses append-only files, the B-tree root node must be rewritten every time the file is updated. However, old portions of the file will never change, so every old B-tree root, should you happen to have a pointer to it, will also point to a consistent snapshot of the database.
Early in the book we explained how the MVCC system uses the document’s
_revvalue to ensure that only one person can change a document version. The B-tree is used to look up the existing _rev value for comparison. By the time a write is accepted, the B-tree can expect it to be an authoritative version.
Since old versions of documents are not overwritten or deleted when new versions come in, requests that are reading a particular version do not care if new ones are written at the same time. With an often changing document, there could be readers reading three different versions at the same time. Each version was the latest one when a particular client started reading it, but new versions were being written. From the point when a new version is committed, new readers will read the new version while old readers keep reading the old version.
In a B-tree, data is kept only in leaf nodes. CouchDB B-trees append data only to the database file that keeps the B-tree on disk and grows only at the end. Add a new document? The file grows at the end. Delete a document? That gets recorded at the end of the file. The consequence is a robust database file. Computers fail for plenty of reasons, such as power loss or failing hardware. Since CouchDB does not overwrite any existing data, it cannot corrupt anything that has been written and committed to disk already. See Figure 1, “Flat B-tree and append-only”.
Committing is the process of updating the database file to reflect changes. This is done in the file footer, which is the last 4k of the database file. The footer is 2k in size and written twice in succession. First, CouchDB appends any changes to the file and then records the file’s new length in the first database footer. It then force-flushes all changes to disk. It then copies the first footer over to the second 2k of the file and force-flushes again.
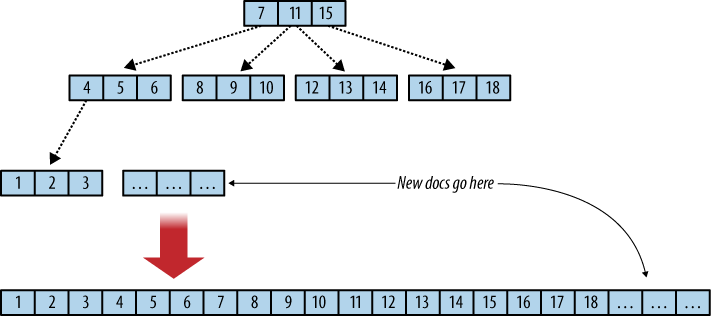
Figure 1. Flat B-tree and append-only
If anywhere in this process a problem occurs—say, power is cut off and CouchDB is restarted later—the database file is in a consistent state and doesn’t need a checkup. CouchDB starts reading the database file backward. When it finds a footer pair, it makes some checks: if the first 2k are corrupt (a footer includes a checksum), CouchDB replaces it with the second footer and all is well. If the second footer is corrupt, CouchDB copies the first 2k over and all is well again. Only once both footers are flushed to disk successfully will CouchDB acknowledge that a write operation was successful. Data is never lost, and data on disk is never corrupted. This design is the reason for CouchDB having no offswitch. You just terminate it when you are done.
There’s a lot more to say about B-trees in general, and if and how SSDs change the runtime behavior. The Wikipedia article on B-trees is a good starting point for further investigations. Scholarpedia includes notes by Dr. Rudolf Bayer, inventor of the B-tree.

